
인공지능에 대한 이해
AI / Machine Learning 소개
Introduction

Artificial Intelligence(AI): 사람의 지능을 흉내내고자하는 모든 분야 ≒ mimic human intelligence
Machine Learning(ML): 데이터를 이용해서 기계가 학습하는 분야 ≒ 기계학습 . data driven approach
Deep Learning: Deep Neural Networks를 통해 기계학습하는 분야 ≒ deep neural networks
Machine Learning
기계학습에서의 inputs 예시: 데이터 사진
outputs 예시: 데이터 사진의 정답
기계학습의 특징
: 많은 데이터를 입력시켜서 기계가 스스로 규칙을 찾아내게 함
: 규칙을 찾아내는 프로그램을 기계가 작성
일반적인 programming의 경우
위의 코딩처럼 사람이 직접 프로그래밍을 작성한 후 코딩을 바탕으로 기계가 분류하는 과정을 거침
기계학습의 경우
움직임을 감지하는 센서가 있다고 가정했을 때 센서를 통해 사용자가 어떤 활동을 하는지 유추할 수 있음
위의 각 Label에 해당하는 항목과 비슷한 값(ex. 010100101001....)이 도출되면 그 항목으로 분류 됨
Machine Learning 종류
Supervised Learning(지도 학습)
: 입력 데이터와 정답을 이용한 학습
: 분류(classification), 회귀(regression) → 연속된 숫자 예측
분류(classification)
ex. 스팸 필터 프로그램
: 여러 가지 메일과 발송 기관 등을 샘플로 훈련하여 스팸 메일인지 아닌지를 분류할 수 있도록 훈련
회귀(regression)
ex. 중고차 가격 예측
: 주행거리, 연식, 브랜드 등을 사용해 중고차의 가격을 예측
: 회귀 방법을 사용하기 위해서는 예측 가능한 변수와 레이블이 포함된 대량의 중고차 판매 데이터가 필요
지도 학습 알고리즘
- k-최근접 이웃(kNN : k-Nearest Neighbors)
- 선형 회귀(linear regression)
- 로지스틱 회귀(logistic regression)
- 서포트 벡터 머신(SVC : support vector machines)
- 결정 트리(decision trees)
- 랜덤 포레스트(randome forests)
- 신경망(neural networks)
Unsupervised Learning(비지도 학습)
: 입력 데이터만을 이용한 학습
: 군집화(clustering), 압축(compression)
군집화(clustering)
- 비슷한 특징을 가진 몇 개의 그룹으로 나누는 것
ex. 블로그 방문자들을 그룹으로 묶는 것
: 어떤 블로그에 방문자들을 성별, 날짜, 연령대, 게시글 카테고리 등으로 그룹화하는 것
: 군집의 대표적인 알고리즘에는 k-평균, DBSCAN, 계층 군집 분석 등이 있음
압축(compression)
1. 시각화
: 레이블이 없는 다차원 특성을 가진 데이터셋을 2D 또는 3D로 표현하는 것
: 시각화를 하기 위해서는 데이터 특성을 두 가지로 줄여야 함
: 시각화된 데이터는 구성 패턴을 통해 어떻게 조직되어 있는지 이해할 수 있게 되고 이상치 패턴들을 발견하여 잘못된 정보를 분석할 수 있게 됨
2. 차원 축소
: 데이터의 특성 수를 줄이는 것으로 상관관계가 있는 여러 특성을 하나로 합치는 과정
: 머신러닝 알고리즘의 성능을 향상할 수 있고, 훈련 실행 속도가 빨라지는 등 메모리 사용 공간이 줄어드는 장점이 있음
ex. 자동차의 주행거리와 연식은 상관관계가 높아 자동차의 '마모 정도'라는 하나의 특성으로 합칠 수 있음
Reinforcement Learning(강화 학습)
: trial and error를 통한 학습 → 발생한 결과를 통해 학습
: Action Selection, Policy Learning
ex. 딥마인드의 알파고
: 에이전트가 취한 행동에 대해 보상 또는 벌점을 주어 가장 큰 보상을 받는 방향으로 유도하는 방법
: 여기서 가장 큰 보상을 얻기 위해 에이전트가 해야 할 행동을 선택하는 방법을 정의하게 됨 = 정책
Training and Testing

진행 과정 설명
Training Stage
고양이 데이터 입력(input data)
→ 뉴럴 네트워크에서 데이터 예측(learning system) → 데이터 정답 알려줌(correct output) 정답을 통해 뉴럴 네트워크 학습(learning system) ←
Testing Stage
training stage에서 사용한 데이터가 아닌 새로운 데이터(new input data)
→ 학습된 뉴럴 네트워크로 데이터 예측(learning system) → 최선의 예측 도출(best guess)
Data 소개
Data
: Training set, Validation set, Test set으로 구성
: Training → Tunning(Validation) → Test(Test set은 Testing stage에서만 사용해야 됨)
Testing하기 전에 시스템 성능 평가 → 성능이 좋으면 바로 Testing Stage로 가서 Test 데이터 사용
← 성능이 안 좋으면 데이터나 시스템을 튜닝 . Training Stage로 감
- Training Stage → Training set 사용
- Tunning → Validation set 사용
- Test Stage → Test set 사용
※ 단, Training Stage에서 Test data를 절대로 사용하면 안됨
→ 데이터는 문제에 따라 달라져야 하고, data의 양이 많을수록 좋음
Good Data vs Bad Data
: 편향된 데이터는 지양해야 함
: 데이터가 믿을만한지 항상 고려 / 데이터는 일관성을 가져야 함(데이터의 정답이 달라지면 안됨)
: 데이터의 질도 매우 중요
Artificial Neural Network 소개
Artificial Neural Network

(3, 2), (1, 4), (5, 5), (8, 3): Input Data
1, -3, 0, 5: label(정답을 알려주는 부분)
네모 / 세모: Weight(구해진 가중치를 통해 새로운 input data가 들어왔을 때 알맞은 정답을 구하도록 함)
Perceptron(Artificial Neural Network)
: 인공 신경망의 기본 단위
: 다수의 값을 입력받아 하나의 값으로 출력하는 알고리즘
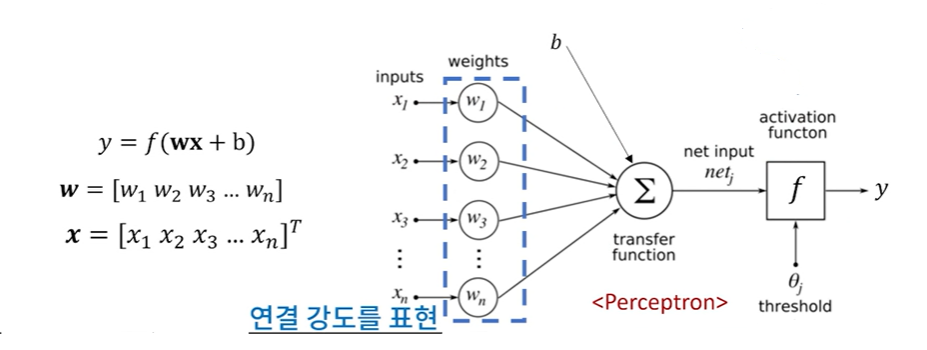
Weights
: 학습해야하는 대상
: 연결 강도를 표현해주는 부분(따라서 각 가중치는 연결 강도가 모두 다름)
Example of Perceptron
: Youtube, TV, 신문 광고료에 따른 다음 달의 판매량 예측 가능


Example of ANN(Logical And)

: AND 혹은 OR의 문제 경우 하나의 Perceptron만을 이용해서 h(x)에 따른 영역을 선형적으로 분리 가능
→ linearly separable
Logical XOR with Perceptron
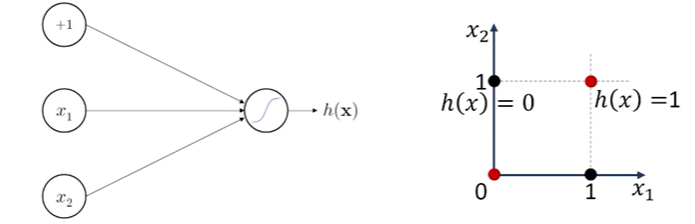
: 하나의 Perceptron만을 이용해서 직선으로 구분할 수 없음
Solution) 더 많은 Perceptron과 Layer가 필요
Logical XOR with Perceptron Solution

→ 위의 그림처럼 layer를 추가하여 비선형적으로 영역 구분 가능
퍼셉트론: 직선 하나로 나눈 영역만 표현할 수 있음
다층 퍼셉트론: 층을 여러개 쌓아 비선형적으로 영역 구분 가능
Importance of Activation functions
: layer를 여러개 쌓게 되면 비선형적으로 공간을 구분할 수 있음
: activation function에 비선형 함수를 사용하면 많은 layer를 쌓았을 때 복잡한 형태로 구분시켜 줌

→ 왼쪽은 선형적으로 구분할 경우
→ 오른쪽은 비선형적으로 구분할 경우
Single - Layer Perceptron & Multi - Layer Perceptron

: hidden layer의 유무가 큰 차이점임
Hidden layer의 역할
: 더 어려운 예측에 성공할 수 있게 함
Deep Learning
Deep Neural Network: hidden layer 수가 최소 2개 이상인 network
: layer는 3개 이상임

Training Neural Networks 소개
Training Neural Networks
: 아무것도 모르는 상태에서 Weights의 초기값은 아무거나 넣고 시작. 보통 0과 가까운 수부터 대입

Neural Network가 얼마나 잘하는지/ 못하는지에 대한 척도 필요
- Loss Function / Cost Function ← 못하는지에 대한 척도 판단 함수(이 과정은 필수적으로 필요)
많이 사용하는 방법 중 한 가지
(Neural Network의 출력과 실제 정답과의 차이)^2
ex. 2가지 광고료 조합에 대하여 Neural Network이 예측한 판매량: (100, 80)
실제 판매량: (105, 78)
L = (105 - 100)^2 + (78 - 80)^2 = 29
→ 제곱 대신에 절대값을 사용해도 됨
Loss Function의 값이 줄어들도록 weight 값들을 조금씩 바꾸는 것
- Weight를 어떻게 바꿔야 Loss Function이 줄는가? → 미분 활용
미분
: 미분값 = 해당 지점에서의 기울기
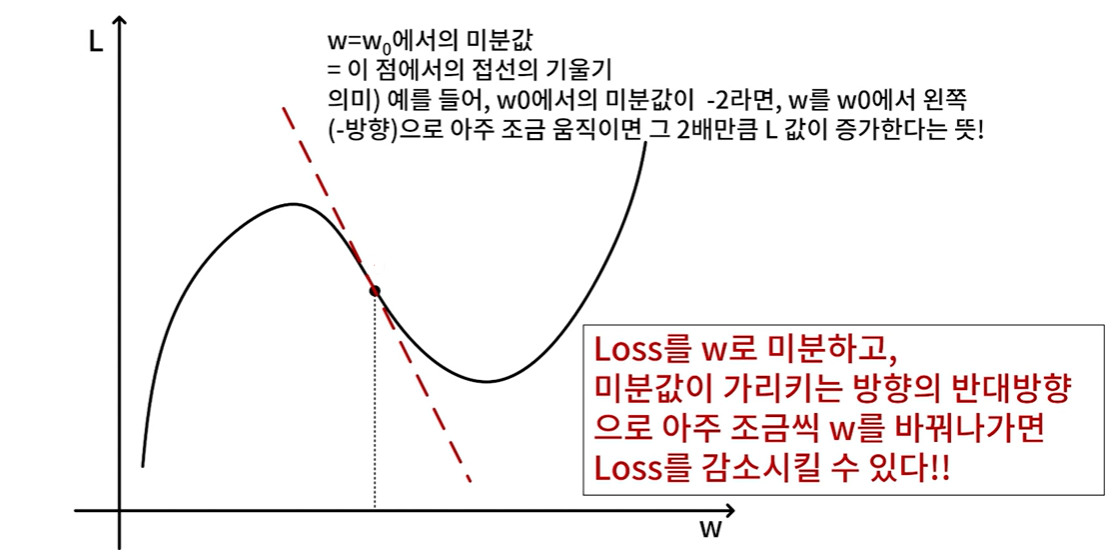
기울기 하강

→ 포물선의 대칭축을 기준으로 오른쪽 영역 에서 한 지점을 초기값으로 설정했다고 가정
: 이 경우 오른쪽 영역의 기울기 즉 미분값은 양수
: 갱신 시 θ는 감소하여 최솟값 지점으로 가깝게 이동
기울기 상승
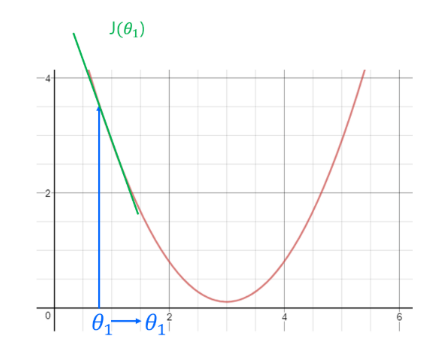
→ 포물선의 대칭축을 기준으로 왼쪽 영역 에서 한 지점을 초기값으로 설정했다고 가정
: 이 경우 왼쪽 영역의 기울기 즉 미분값은 음수
: 갱신 시 θ는 증가 하여 최솟값 지점으로 가깝게 이동
Gradient descent
: Loss Function의 미분(Gradient)를 이용해 Weight를 update하는 방법
: 손실을 최소화하는 방식으로 가중치를 업데이트 해야 함


미분 계산 예시
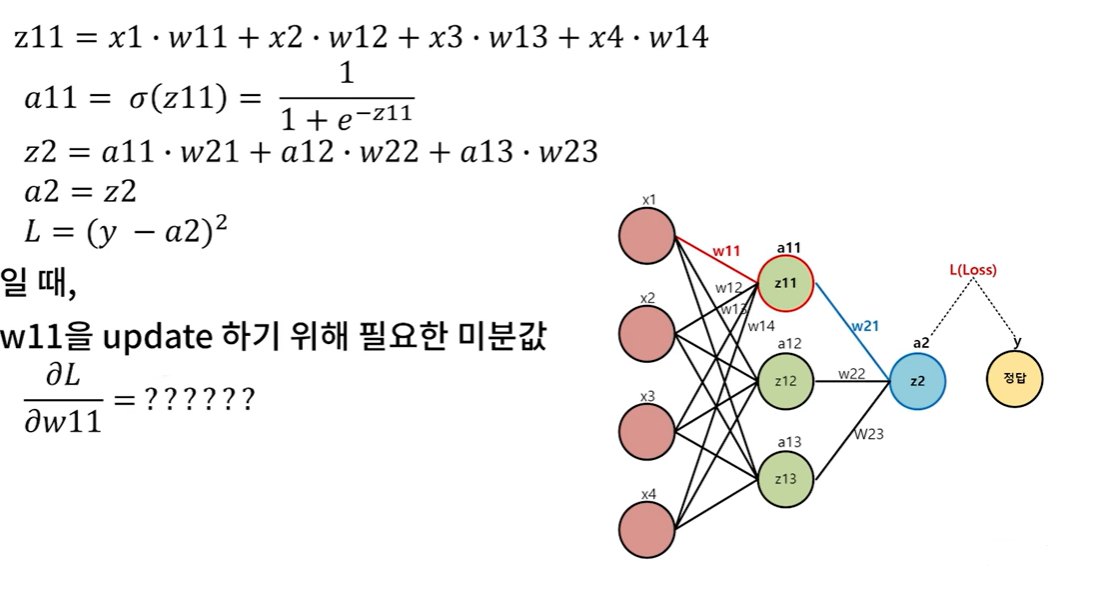
Back Propagation
: Loss부터 거꾸로 한 단계씩 미분하기

→ Loss로부터 거꾸로 한 단계씩 미분 값을 구하고, 이 값을 chain rule에 의해 곱해가면서 weight에 대한 gradient를 구하는 방법
Key Components of Deep Learning
data: 모델이 배울 데이터가 필요
model: 데이터를 어떻게 변형할건지에 대한 모델이 중요
loss function: 모델이 잘 작동하는지를 판단하는 함수 중요
algorithm: 손실을 최소화하는 파라미터들을 적용할 알고리즘이 중요 → gradient descent
출처:
패스트 캠퍼스