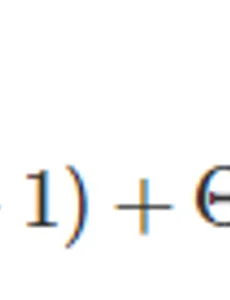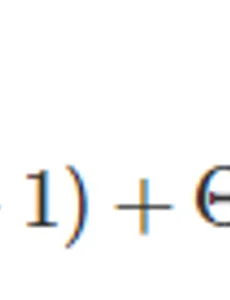 Quick Sorting & Hash function
1. Describe linear median finding algorithm, Show that its time complexity is Θ(n) 일반적인 quick sort의 시간 복잡도는 최선일 때 O(nlogn)이고, 최악일 때 O(n^2)만큼 걸린다. 수열의 길이가 n일 때 알고리즘의 수행 시간의 기댓값을 T(n)이라고 하자. 수열이 a1, ... , an으로 주어졌을 때, 이를 오름차순으로 정렬한 것을 b1, ... , bn이라고 하면 {a1, ... , an} = {b1, ... , bn}고, b1 < ... < bn 이다. 만약 알고리즘이 단계 2에서 x = b_j+1을 골랐다고 하자. 그러면 |A < x| = j이고 |A ≥ x| = n − j가 된다. 따라서 다음 재귀 호출에서 살아 남..
2023. 4. 1.
Quick Sorting & Hash function
1. Describe linear median finding algorithm, Show that its time complexity is Θ(n) 일반적인 quick sort의 시간 복잡도는 최선일 때 O(nlogn)이고, 최악일 때 O(n^2)만큼 걸린다. 수열의 길이가 n일 때 알고리즘의 수행 시간의 기댓값을 T(n)이라고 하자. 수열이 a1, ... , an으로 주어졌을 때, 이를 오름차순으로 정렬한 것을 b1, ... , bn이라고 하면 {a1, ... , an} = {b1, ... , bn}고, b1 < ... < bn 이다. 만약 알고리즘이 단계 2에서 x = b_j+1을 골랐다고 하자. 그러면 |A < x| = j이고 |A ≥ x| = n − j가 된다. 따라서 다음 재귀 호출에서 살아 남..
2023. 4. 1.