이번 시간에는 Gaussian-splatting의 GT data를 만드는 방법에 대해 소개하고자 한다.
우선, GT data를 만들기 위해 정확한 camera parameter와 point cloud를 초기 Gaussian-splatting의 입력으로 사용했다.
하지만, 해당 조건으로 Gaussian-splatting을 train할 경우 3D Gaussian이 새로 생성되고 삭제되는 과정에서 아래와 그림과 같이 배경과 3D model에 대해 둘 다 최적화됐다.
의도한 결과는 3D model 안에서만 3D gaussian이 생성되도록 하는거였지만, 최종 결과는 배경과 3D model 둘에 대해 모두 3D gaussian이 생성됐다.

그래서 결국 3D gaussian을 최적화시킬 때, initial point cloud의 position을 고정시킨 상태에서 3D gaussian들이 최적화되도록 코드를 변경해봤다. 아래는 코드를 수정한 파일(gaussian_model.py)이다.
(point cloud의 position만 고정시켜주면 되기 때문에 사실상 point cloud position에 대한 gradient를 막아주기만 하면 된다.)
import torch
import numpy as np
from utils.general_utils import inverse_sigmoid, get_expon_lr_func, build_rotation
from torch import nn
import os
from utils.system_utils import mkdir_p
from plyfile import PlyData, PlyElement
from utils.sh_utils import RGB2SH
from simple_knn._C import distCUDA2
from utils.graphics_utils import BasicPointCloud
from utils.general_utils import strip_symmetric, build_scaling_rotation
class GaussianModel:
def setup_functions(self):
def build_covariance_from_scaling_rotation(scaling, scaling_modifier, rotation):
L = build_scaling_rotation(scaling_modifier * scaling, rotation)
actual_covariance = L @ L.transpose(1, 2)
symm = strip_symmetric(actual_covariance)
return symm
self.scaling_activation = torch.exp
self.scaling_inverse_activation = torch.log
self.covariance_activation = build_covariance_from_scaling_rotation
self.opacity_activation = torch.sigmoid
self.inverse_opacity_activation = inverse_sigmoid
self.rotation_activation = torch.nn.functional.normalize
def __init__(self, sh_degree : int):
self.active_sh_degree = 0
self.max_sh_degree = sh_degree
self._xyz = torch.empty(0)
self._features_dc = torch.empty(0)
self._features_rest = torch.empty(0)
self._scaling = torch.empty(0)
self._rotation = torch.empty(0)
self._opacity = torch.empty(0)
self.max_radii2D = torch.empty(0)
self.xyz_gradient_accum = torch.empty(0)
self.denom = torch.empty(0)
self.optimizer = None
self.percent_dense = 0
self.spatial_lr_scale = 0
self.setup_functions()
def capture(self):
return (
self.active_sh_degree,
self._xyz,
self._features_dc,
self._features_rest,
self._scaling,
self._rotation,
self._opacity,
self.max_radii2D,
self.xyz_gradient_accum,
self.denom,
self.optimizer.state_dict(),
self.spatial_lr_scale,
)
def restore(self, model_args, training_args):
(self.active_sh_degree,
self._xyz,
self._features_dc,
self._features_rest,
self._scaling,
self._rotation,
self._opacity,
self.max_radii2D,
xyz_gradient_accum,
denom,
opt_dict,
self.spatial_lr_scale) = model_args
self.training_setup(training_args)
self.xyz_gradient_accum = xyz_gradient_accum
self.denom = denom
self.optimizer.load_state_dict(opt_dict)
@property
def get_scaling(self):
return self.scaling_activation(self._scaling)
@property
def get_rotation(self):
return self.rotation_activation(self._rotation)
@property
def get_xyz(self):
return self._xyz
@property
def get_features(self):
features_dc = self._features_dc
features_rest = self._features_rest
return torch.cat((features_dc, features_rest), dim=1)
@property
def get_opacity(self):
return self.opacity_activation(self._opacity)
def get_covariance(self, scaling_modifier = 1):
return self.covariance_activation(self.get_scaling, scaling_modifier, self._rotation)
def oneupSHdegree(self):
if self.active_sh_degree < self.max_sh_degree:
self.active_sh_degree += 1
def create_from_pcd(self, pcd : BasicPointCloud, spatial_lr_scale : float):
self.spatial_lr_scale = spatial_lr_scale
fused_point_cloud = torch.tensor(np.asarray(pcd.points)).float().cuda() # 3D point cloud에서 추출한 초기 point position ==> 3D gaussian의 초기 position(M)으로 사용
fused_color = RGB2SH(torch.tensor(np.asarray(pcd.colors)).float().cuda())
features = torch.zeros((fused_color.shape[0], 3, (self.max_sh_degree + 1) ** 2)).float().cuda()
features[:, :3, 0 ] = fused_color
features[:, 3:, 1:] = 0.0
print("Number of points at initialisation : ", fused_point_cloud.shape[0])
dist2 = torch.clamp_min(distCUDA2(torch.from_numpy(np.asarray(pcd.points)).float().cuda()), 0.0000001)
scales = torch.log(torch.sqrt(dist2))[...,None].repeat(1, 3)
rots = torch.zeros((fused_point_cloud.shape[0], 4), device="cuda")
rots[:, 0] = 1
opacities = inverse_sigmoid(0.1 * torch.ones((fused_point_cloud.shape[0], 1), dtype=torch.float, device="cuda"))
#self._xyz = nn.Parameter(fused_point_cloud.requires_grad_(True))
self._xyz = nn.Parameter(fused_point_cloud.requires_grad_(False))
self._features_dc = nn.Parameter(features[:,:,0:1].transpose(1, 2).contiguous().requires_grad_(True))
self._features_rest = nn.Parameter(features[:,:,1:].transpose(1, 2).contiguous().requires_grad_(True))
self._scaling = nn.Parameter(scales.requires_grad_(True))
self._rotation = nn.Parameter(rots.requires_grad_(True))
self._opacity = nn.Parameter(opacities.requires_grad_(True))
self.max_radii2D = torch.zeros((self.get_xyz.shape[0]), device="cuda")
def training_setup(self, training_args):
self.percent_dense = training_args.percent_dense
self.xyz_gradient_accum = torch.zeros((self.get_xyz.shape[0], 1), device="cuda")
self.denom = torch.zeros((self.get_xyz.shape[0], 1), device="cuda")
l = [
#{'params': [self._xyz], 'lr': training_args.position_lr_init * self.spatial_lr_scale, "name": "xyz"},
{'params': [self._xyz], 'lr': 0.0, "name": "xyz"}, ###
{'params': [self._features_dc], 'lr': training_args.feature_lr, "name": "f_dc"},
{'params': [self._features_rest], 'lr': training_args.feature_lr / 20.0, "name": "f_rest"},
{'params': [self._opacity], 'lr': training_args.opacity_lr, "name": "opacity"},
{'params': [self._scaling], 'lr': training_args.scaling_lr, "name": "scaling"},
{'params': [self._rotation], 'lr': training_args.rotation_lr, "name": "rotation"}
]
self.optimizer = torch.optim.Adam(l, lr=0.0, eps=1e-15)
self.xyz_scheduler_args = get_expon_lr_func(lr_init=training_args.position_lr_init*self.spatial_lr_scale,
lr_final=training_args.position_lr_final*self.spatial_lr_scale,
lr_delay_mult=training_args.position_lr_delay_mult,
max_steps=training_args.position_lr_max_steps) # gaussian position에 대한 학습률 최적화
def update_learning_rate(self, iteration):
''' Learning rate scheduling per step '''
for param_group in self.optimizer.param_groups:
if param_group["name"] == "xyz":
#lr = self.xyz_scheduler_args(iteration)
#param_group['lr'] = lr
#return lr
continue # learning rate 변경 무시
def construct_list_of_attributes(self):
l = ['x', 'y', 'z', 'nx', 'ny', 'nz']
# All channels except the 3 DC
for i in range(self._features_dc.shape[1]*self._features_dc.shape[2]):
l.append('f_dc_{}'.format(i))
for i in range(self._features_rest.shape[1]*self._features_rest.shape[2]):
l.append('f_rest_{}'.format(i))
l.append('opacity')
for i in range(self._scaling.shape[1]):
l.append('scale_{}'.format(i))
for i in range(self._rotation.shape[1]):
l.append('rot_{}'.format(i))
return l
def save_ply(self, path):
mkdir_p(os.path.dirname(path))
xyz = self._xyz.detach().cpu().numpy()
normals = np.zeros_like(xyz)
f_dc = self._features_dc.detach().transpose(1, 2).flatten(start_dim=1).contiguous().cpu().numpy()
f_rest = self._features_rest.detach().transpose(1, 2).flatten(start_dim=1).contiguous().cpu().numpy()
opacities = self._opacity.detach().cpu().numpy()
scale = self._scaling.detach().cpu().numpy()
rotation = self._rotation.detach().cpu().numpy()
dtype_full = [(attribute, 'f4') for attribute in self.construct_list_of_attributes()]
elements = np.empty(xyz.shape[0], dtype=dtype_full)
attributes = np.concatenate((xyz, normals, f_dc, f_rest, opacities, scale, rotation), axis=1)
elements[:] = list(map(tuple, attributes))
el = PlyElement.describe(elements, 'vertex')
PlyData([el]).write(path)
def reset_opacity(self):
opacities_new = inverse_sigmoid(torch.min(self.get_opacity, torch.ones_like(self.get_opacity)*0.01))
optimizable_tensors = self.replace_tensor_to_optimizer(opacities_new, "opacity")
self._opacity = optimizable_tensors["opacity"]
def load_ply(self, path):
plydata = PlyData.read(path)
xyz = np.stack((np.asarray(plydata.elements[0]["x"]),
np.asarray(plydata.elements[0]["y"]),
np.asarray(plydata.elements[0]["z"])), axis=1)
opacities = np.asarray(plydata.elements[0]["opacity"])[..., np.newaxis]
features_dc = np.zeros((xyz.shape[0], 3, 1))
features_dc[:, 0, 0] = np.asarray(plydata.elements[0]["f_dc_0"])
features_dc[:, 1, 0] = np.asarray(plydata.elements[0]["f_dc_1"])
features_dc[:, 2, 0] = np.asarray(plydata.elements[0]["f_dc_2"])
extra_f_names = [p.name for p in plydata.elements[0].properties if p.name.startswith("f_rest_")]
extra_f_names = sorted(extra_f_names, key = lambda x: int(x.split('_')[-1]))
assert len(extra_f_names)==3*(self.max_sh_degree + 1) ** 2 - 3
features_extra = np.zeros((xyz.shape[0], len(extra_f_names)))
for idx, attr_name in enumerate(extra_f_names):
features_extra[:, idx] = np.asarray(plydata.elements[0][attr_name])
# Reshape (P,F*SH_coeffs) to (P, F, SH_coeffs except DC)
features_extra = features_extra.reshape((features_extra.shape[0], 3, (self.max_sh_degree + 1) ** 2 - 1))
scale_names = [p.name for p in plydata.elements[0].properties if p.name.startswith("scale_")]
scale_names = sorted(scale_names, key = lambda x: int(x.split('_')[-1]))
scales = np.zeros((xyz.shape[0], len(scale_names)))
for idx, attr_name in enumerate(scale_names):
scales[:, idx] = np.asarray(plydata.elements[0][attr_name])
rot_names = [p.name for p in plydata.elements[0].properties if p.name.startswith("rot")]
rot_names = sorted(rot_names, key = lambda x: int(x.split('_')[-1]))
rots = np.zeros((xyz.shape[0], len(rot_names)))
for idx, attr_name in enumerate(rot_names):
rots[:, idx] = np.asarray(plydata.elements[0][attr_name])
#self._xyz = nn.Parameter(torch.tensor(xyz, dtype=torch.float, device="cuda").requires_grad_(True))
self._xyz = nn.Parameter(torch.tensor(xyz, dtype=torch.float, device="cuda").requires_grad_(False))
self._features_dc = nn.Parameter(torch.tensor(features_dc, dtype=torch.float, device="cuda").transpose(1, 2).contiguous().requires_grad_(True))
self._features_rest = nn.Parameter(torch.tensor(features_extra, dtype=torch.float, device="cuda").transpose(1, 2).contiguous().requires_grad_(True))
self._opacity = nn.Parameter(torch.tensor(opacities, dtype=torch.float, device="cuda").requires_grad_(True))
self._scaling = nn.Parameter(torch.tensor(scales, dtype=torch.float, device="cuda").requires_grad_(True))
self._rotation = nn.Parameter(torch.tensor(rots, dtype=torch.float, device="cuda").requires_grad_(True))
self.active_sh_degree = self.max_sh_degree
def replace_tensor_to_optimizer(self, tensor, name):
optimizable_tensors = {}
for group in self.optimizer.param_groups:
if group["name"] == name:
stored_state = self.optimizer.state.get(group['params'][0], None)
stored_state["exp_avg"] = torch.zeros_like(tensor)
stored_state["exp_avg_sq"] = torch.zeros_like(tensor)
del self.optimizer.state[group['params'][0]]
#group["params"][0] = nn.Parameter(tensor.requires_grad_(True))
if group["name"] == "xyz":
group["params"][0] = nn.Parameter(tensor.requires_grad_(False))
else:
group["params"][0] = nn.Parameter(tensor.requires_grad_(True))
self.optimizer.state[group['params'][0]] = stored_state
optimizable_tensors[group["name"]] = group["params"][0]
return optimizable_tensors
def _prune_optimizer(self, mask):
optimizable_tensors = {}
for group in self.optimizer.param_groups:
stored_state = self.optimizer.state.get(group['params'][0], None)
if stored_state is not None:
stored_state["exp_avg"] = stored_state["exp_avg"][mask]
stored_state["exp_avg_sq"] = stored_state["exp_avg_sq"][mask]
del self.optimizer.state[group['params'][0]]
#group["params"][0] = nn.Parameter((group["params"][0][mask].requires_grad_(True)))
if group["name"] == "xyz":
group["params"][0] = nn.Parameter((group["params"][0][mask].requires_grad_(False)))
else:
group["params"][0] = nn.Parameter((group["params"][0][mask].requires_grad_(True)))
self.optimizer.state[group['params'][0]] = stored_state
optimizable_tensors[group["name"]] = group["params"][0]
else:
if group["name"] == "xyz":
group["params"][0] = nn.Parameter(group["params"][0][mask].requires_grad_(False))
else:
group["params"][0] = nn.Parameter(group["params"][0][mask].requires_grad_(True))
#group["params"][0] = nn.Parameter(group["params"][0][mask].requires_grad_(True))
optimizable_tensors[group["name"]] = group["params"][0]
return optimizable_tensors
def prune_points(self, mask):
valid_points_mask = ~mask
optimizable_tensors = self._prune_optimizer(valid_points_mask)
self._xyz = optimizable_tensors["xyz"]
self._features_dc = optimizable_tensors["f_dc"]
self._features_rest = optimizable_tensors["f_rest"]
self._opacity = optimizable_tensors["opacity"]
self._scaling = optimizable_tensors["scaling"]
self._rotation = optimizable_tensors["rotation"]
self.xyz_gradient_accum = self.xyz_gradient_accum[valid_points_mask]
self.denom = self.denom[valid_points_mask]
self.max_radii2D = self.max_radii2D[valid_points_mask]
def cat_tensors_to_optimizer(self, tensors_dict):
optimizable_tensors = {}
for group in self.optimizer.param_groups:
assert len(group["params"]) == 1
extension_tensor = tensors_dict[group["name"]]
stored_state = self.optimizer.state.get(group['params'][0], None)
if stored_state is not None:
stored_state["exp_avg"] = torch.cat((stored_state["exp_avg"], torch.zeros_like(extension_tensor)), dim=0)
stored_state["exp_avg_sq"] = torch.cat((stored_state["exp_avg_sq"], torch.zeros_like(extension_tensor)), dim=0)
del self.optimizer.state[group['params'][0]]
#group["params"][0] = nn.Parameter(torch.cat((group["params"][0], extension_tensor), dim=0).requires_grad_(True))
if group["name"] == "xyz":
group["params"][0] = nn.Parameter(torch.cat((group["params"][0], extension_tensor), dim=0).requires_grad_(False))
else:
group["params"][0] = nn.Parameter(torch.cat((group["params"][0], extension_tensor), dim=0).requires_grad_(True))
self.optimizer.state[group['params'][0]] = stored_state
optimizable_tensors[group["name"]] = group["params"][0]
else:
#group["params"][0] = nn.Parameter(torch.cat((group["params"][0], extension_tensor), dim=0).requires_grad_(True))
if group["name"] == "xyz":
group["params"][0] = nn.Parameter(torch.cat((group["params"][0], extension_tensor), dim=0).requires_grad_(False))
else:
group["params"][0] = nn.Parameter(torch.cat((group["params"][0], extension_tensor), dim=0).requires_grad_(True))
optimizable_tensors[group["name"]] = group["params"][0]
return optimizable_tensors
def densification_postfix(self, new_xyz, new_features_dc, new_features_rest, new_opacities, new_scaling, new_rotation):
d = {"xyz": new_xyz,
"f_dc": new_features_dc,
"f_rest": new_features_rest,
"opacity": new_opacities,
"scaling" : new_scaling,
"rotation" : new_rotation}
optimizable_tensors = self.cat_tensors_to_optimizer(d)
self._xyz = optimizable_tensors["xyz"]
self._features_dc = optimizable_tensors["f_dc"]
self._features_rest = optimizable_tensors["f_rest"]
self._opacity = optimizable_tensors["opacity"]
self._scaling = optimizable_tensors["scaling"]
self._rotation = optimizable_tensors["rotation"]
self.xyz_gradient_accum = torch.zeros((self.get_xyz.shape[0], 1), device="cuda")
self.denom = torch.zeros((self.get_xyz.shape[0], 1), device="cuda")
self.max_radii2D = torch.zeros((self.get_xyz.shape[0]), device="cuda")
def densify_and_split(self, grads, grad_threshold, scene_extent, N=2): # gaussian split(minimize)
n_init_points = self.get_xyz.shape[0]
# Extract points that satisfy the gradient condition
padded_grad = torch.zeros((n_init_points), device="cuda")
padded_grad[:grads.shape[0]] = grads.squeeze()
selected_pts_mask = torch.where(padded_grad >= grad_threshold, True, False)
selected_pts_mask = torch.logical_and(selected_pts_mask,
torch.max(self.get_scaling, dim=1).values > self.percent_dense*scene_extent)
stds = self.get_scaling[selected_pts_mask].repeat(N,1)
means =torch.zeros((stds.size(0), 3),device="cuda")
samples = torch.normal(mean=means, std=stds)
rots = build_rotation(self._rotation[selected_pts_mask]).repeat(N,1,1)
#new_xyz = torch.bmm(rots, samples.unsqueeze(-1)).squeeze(-1) + self.get_xyz[selected_pts_mask].repeat(N, 1)
new_xyz = self.get_xyz[selected_pts_mask].repeat(N, 1) ###
new_scaling = self.scaling_inverse_activation(self.get_scaling[selected_pts_mask].repeat(N,1) / (0.8*N))
new_rotation = self._rotation[selected_pts_mask].repeat(N,1)
new_features_dc = self._features_dc[selected_pts_mask].repeat(N,1,1)
new_features_rest = self._features_rest[selected_pts_mask].repeat(N,1,1)
new_opacity = self._opacity[selected_pts_mask].repeat(N,1)
self.densification_postfix(new_xyz, new_features_dc, new_features_rest, new_opacity, new_scaling, new_rotation)
prune_filter = torch.cat((selected_pts_mask, torch.zeros(N * selected_pts_mask.sum(), device="cuda", dtype=bool)))
self.prune_points(prune_filter)
def densify_and_clone(self, grads, grad_threshold, scene_extent): # gaussian clone(maximize)
# Extract points that satisfy the gradient condition
selected_pts_mask = torch.where(torch.norm(grads, dim=-1) >= grad_threshold, True, False)
selected_pts_mask = torch.logical_and(selected_pts_mask,
torch.max(self.get_scaling, dim=1).values <= self.percent_dense*scene_extent)
new_xyz = self._xyz[selected_pts_mask]
new_features_dc = self._features_dc[selected_pts_mask]
new_features_rest = self._features_rest[selected_pts_mask]
new_opacities = self._opacity[selected_pts_mask]
new_scaling = self._scaling[selected_pts_mask]
new_rotation = self._rotation[selected_pts_mask]
self.densification_postfix(new_xyz, new_features_dc, new_features_rest, new_opacities, new_scaling, new_rotation)
def densify_and_prune(self, max_grad, min_opacity, extent, max_screen_size): # remove gaussian
# self.xyz_gradient_accum: 3D gaussian position을 최적화하는 과정에서 3D gaussian position의 변화 정도를 나타냄
# self.xyz_gradient_accum가 크면 3D gaussian position이 크게 조정돼야 함
# self.xyz_gradient_accum가 작으면 3D gaussian position이 이미 최적의 위치와 가까움을 의미
grads = self.xyz_gradient_accum / self.denom
grads[grads.isnan()] = 0.0
self.densify_and_clone(grads, max_grad, extent)
self.densify_and_split(grads, max_grad, extent)
prune_mask = (self.get_opacity < min_opacity).squeeze()
if max_screen_size:
big_points_vs = self.max_radii2D > max_screen_size
big_points_ws = self.get_scaling.max(dim=1).values > 0.1 * extent
prune_mask = torch.logical_or(torch.logical_or(prune_mask, big_points_vs), big_points_ws)
self.prune_points(prune_mask)
torch.cuda.empty_cache()
def add_densification_stats(self, viewspace_point_tensor, update_filter):
self.xyz_gradient_accum[update_filter] += torch.norm(viewspace_point_tensor.grad[update_filter,:2], dim=-1, keepdim=True)
self.denom[update_filter] += 1
그렇게 수정했을 때, 아래와 같은 결과물이 나온다. intial point cloud는 80000개인데, output은 약 50000개로 많이 줄어든 결과물을 확인할 수 있었다. 그리고 여전히 point cloud의 위치가 고정돼 있더라도 3D model 안에 존재하는 3D gaussian의 RGB가 배경색으로 최적화되는 경우가 존재했다.
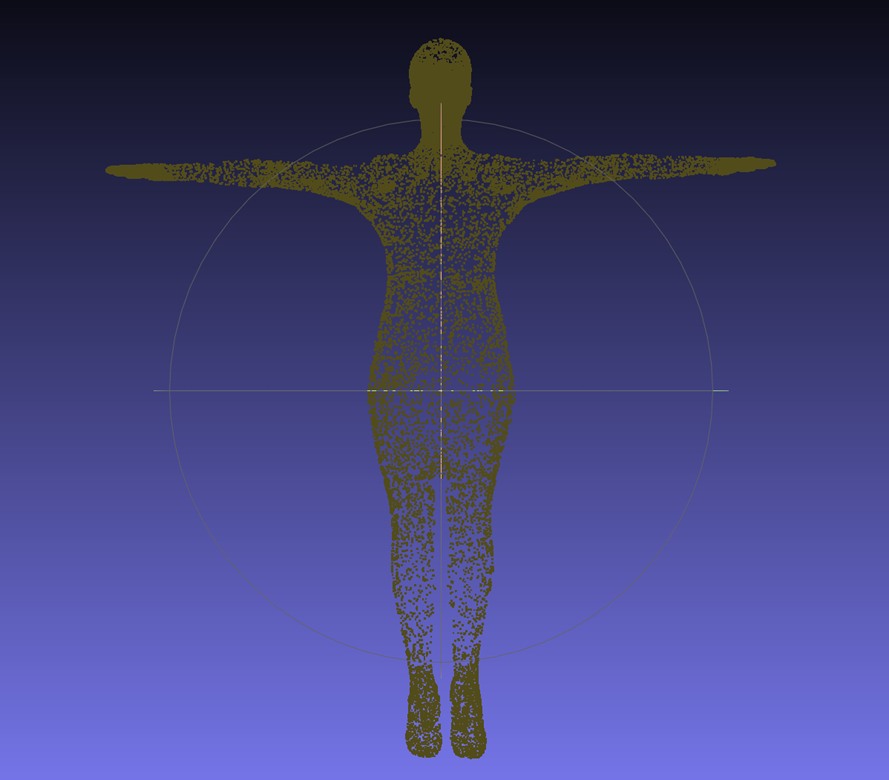

그래서 결국 point cloud의 position을 고정시키지 않고, 배경을 검정색으로 두고 배경의 opacity도 0으로 뒀을 때 3D gaussian splatting의 결과를 확인해봤다.
다행이도 거의 3D human model에 대해서만 3D gaussian이 최적화됐음을 확인할 수 있었다.
(이러한 이유로 다양한 방식의 3D reconstruction 모델을 학습시킬 때, 일반적으로 RGB 이미지에 Synthetic mask를 씌워서 주변 환경을 모두 검정으로 만든 후 3D reconstruction output을 확인한다고 한다.
그래야지 일반적으로 주변 환경을 제외하고, 3D model에 대해서만 제대로 reconstruction이 되기 때문이다.)
White cloth


Black Cloth
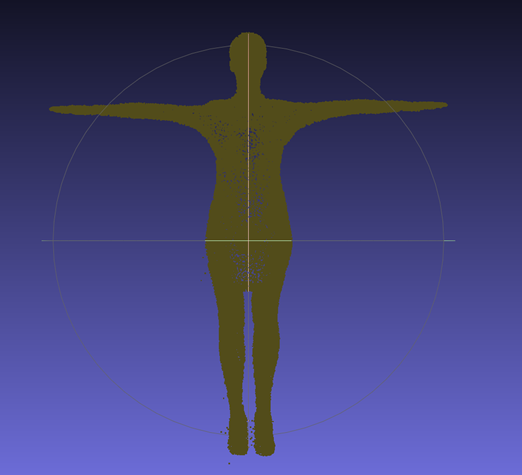

Appendix
추가적으로, view마다 3D model은 고정으로 두고 배경만 random하게 바뀌었을 때도 3D model에 대해서만 point cloud의 최적화가 잘 될까라는 의문이 생겨서 아래와 같이 추가적인 실습을 진행해봤다.

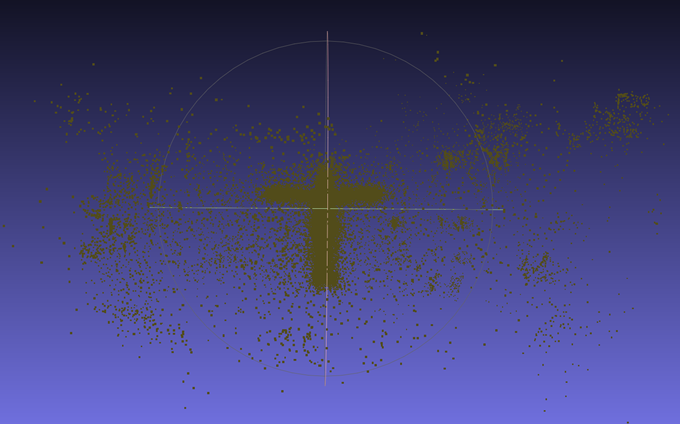
아래는 결과물에 해당하는 point cloud와 3D gaussian-splatting viewer이다. 주어진 random한 배경색에 point cloud가 최적화된 모습이다.

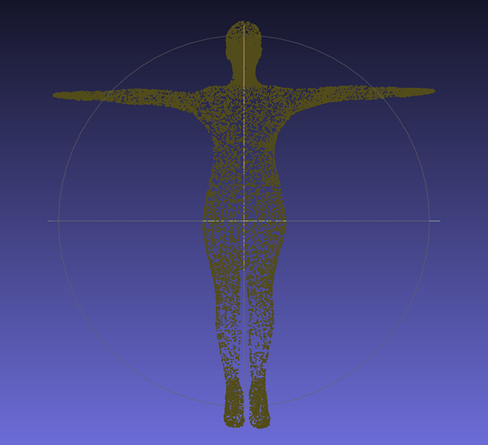
아래는 initial point cloud의 position을 fix한 결과이다. 여전히 3D model에 대한 point cloud 안에서 random한 배경색이 최적화된 모습이다.

'실습 & 활동 > Computer vision' 카테고리의 다른 글
| [SMPL] 실습 코드 분석 (0) | 2024.05.08 |
|---|---|
| [SMPL] single human synthetic data SMPL 실습 결과 (0) | 2024.05.07 |
| [SMPL] Mesh package clone (0) | 2024.04.23 |
| [WSL-Ubuntu] Pytorch & Pytorch3d & CUDA 버전 설치 (0) | 2024.04.23 |
| [Gaussian Splatting] Colmap vs. Correct camera parameter (0) | 2024.04.12 |


