Supervised Learning
지도 학습은 말 그대로 정답이 있는 데이터를 활용해 데이터를 학습시키는 것
입력 값(X data)이 주어지면 입력값에 대한 Label(Y data)를 주어 학습시키며 대표적으로 분류, 회귀 문제가 있음
Machine Learning Problem
- Binary classification(이항 분류)
- Multi-class classification(다중 클래스 분류)
- Regression(회귀)

Supervised Learning
: 입력값 X를 넣었을 때 나오는 Y의 관계를 설명하는 함수 h(x)(학습하는 부분)를 정의하는 것으로,
(X1, Y1)....(Xn, Yn) 형식의 데이터셋을 사용
: X , Y(label(정답)) 출력값으로 모델을 학습시킨 후 접하지 않았던 샘플 X에 대한 Y 값을 예측하는 방식
Regression
실수형 변수를 통해 예측하여 예측 결과값이 연속성을 지니고 있는 경우
Classification
주어진 사진 상단에 label(정답)이 있고, 아래에 입력(X값)에 해당하는 사진들이 있음
Supervised Learning Process
Phase 1: 머신러닝 모델은 training sample에서의 Y(label) 데이터를 통해 출력을 정확하게
맞출 수 있도록 학습함
→ 모델의 parameter 값을 변경해 나가면서 모델의 정확도를 높임
Phase 2: testing sample을 통해 모델의 성능을 확인해가는 과정을 거침
Supervised Learning Example
입력 표현 == 입력 feature : classification에 효과적인 feature를 도입해야 함아래 예시에서의 입력값은
price(자동차 가격), engine power(엔진)으로 설정
위의 예제는 Family Car 인지 아닌지를 판단하고자 하는 문제인데, 이 때 Family Car에 속할 경우 Positive samle, 반대의 경우 Negative Sample로 지칭함

Target function
: 많지 않은 데이터로 정확도가 높은 분류를 할 수 있는 이상적인 모델을 만들기 위해서는 target function f(x)에 근접해야 함 → 이러한 함수를 hypothesis h라고 함

Learning model
모델의 학습에 있어 중요한 요소
- Feature Selection: 문제의 적절한 Feature를 선정하여 학습
- Model Selection: 주어진 문제에 가장 적합한 모델을 선택하여 문제 해결
- Optimization: 모델 파라미터를 최적화하여 성능 최대화
Generalization error를 줄이는 방법
model Generalization: 존재하는 모든 데이터에 대한 모델을 구성할 수 없기 때문에 데이터의 결핍으로 인한
불확실성을 최소화하기 위해 일반화가 중요
즉, 모르는 데이터에도 우수한 성능을 제공해야 하는 것이 목표이며, Generalization Error의 최소화가 목적
목표 함수는 이상적인 함수이기에 직접적으로 generalization error를 줄일 수 없음
→ Training Error, Validation Error, Test Set Error를 이용해 error 최소화
Error
: e(h(x), y)으로 표현 됨
h(x) = model의 출력, y = 정답
대표적인 error
: squared error - model의 출력과 정답과의 차이를 제곱해 계산
: binary error - model의 출력과 정답이 틀리면 1을, model의 출력과 정답이 맞으면 0을 출력
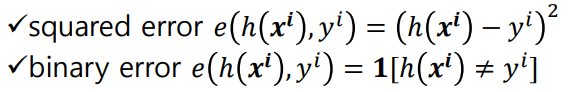
overall error - data sample에서 발생하는 모든 sample들의 pointwise error를 합쳐서 overall error 계산
overall error == loss function, cost function
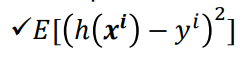
주요 Error
E_train
: 모델을 주어진 data set에 맞춰 학습하는데 사용하는 error
: 주어진 sample에서 model parameter를 최적화하는데 사용
E_test
: model이 실제 세계에서 사용됐을 때 발생하는 error
목표 - E_test와 E_general을 0으로 근사시키는게 중요
모델의 error를 줄이기 위해
- E_train와 E_test이 가까워지도록 학습
- E_train의 값이 0에 가까워지도록 학습
1. E_train와 E_test이 가까워지도록 학습 - 최악의 경우
problem) 모델의 분산이 커져, 학습데이터셋에 의존하는 overfitting 문제가 발생
solution) 정규화나 더 많은 데이터 셋으로 해결할 수 있음
2. E_train의 값이 0에 가까워지도록 학습 - 최악의 경우
problem) 모델의 bias가 커져, underfitting 문제가 발생
solution) 최적화나 더 복잡한 모델을 사용해 해결할 수 있음
Model 정확도를 높이는 방법
bias 줄이기 / model 일반화 높이기 / variance 줄이기
따라서, variance와 bias 사이에는 서로 반비례 관계인 trade-off 관계가 존재
Total Loss = Bias + Varinace (+ noise)
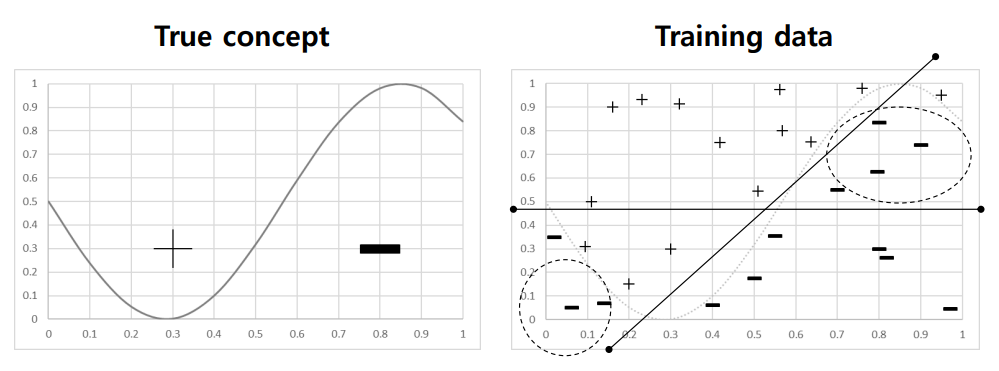
Underfitting
: 모델의 bias가 클 때 발생
: 그림과 같은 linear한 모델은 decision boudary에 효과적으로 근사할 수 없음
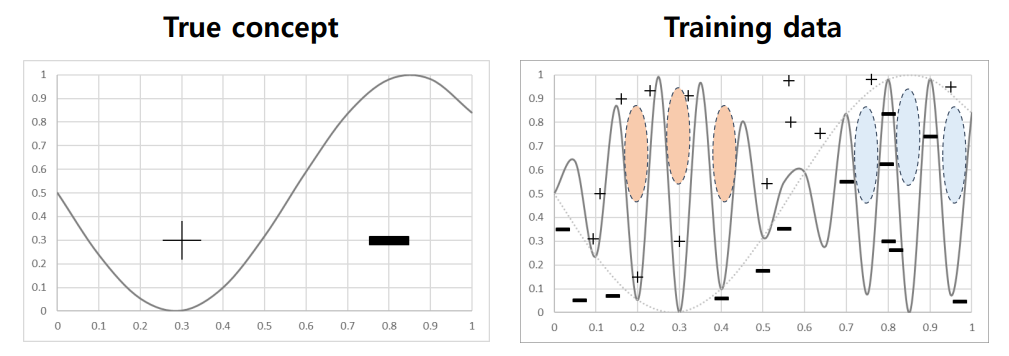
Overfitting
: 모델의 variance가 클 때 발생
주황색 - 플러스 영역이 마이너스 영역으로 됨
파란색 - 마이너스 영역이 플러스 영역으로 됨
: decision boudary가 과하게 복잡해짐
Bias-variance trade-off

underfitting zone: bias 높음 / variance 낮음(데이터가 흩어져 있음) - 분류가 잘 됨
overfitting zone: bias 낮음 / variance 높음(데이터가 모여 있음) - 분류가 힘듦
최적의 모델을 만들기 위해서는 generalization error가 최소화되는 지점으로 설정해야 함
Avoid overfitting
무수히 많은 데이터를 확보하는데 어려움이 있어 Data augmentation(데이터 증강)이 등장
→ Regularization, Ensemble
Cross - validation(CV)
: 학습 데이터셋을 k개의 그룹으로 나누어 (k-1)개의 그룹은 학습(training data)에 사용하고 1개의 그룹은
성능 평가(validation data)에 사용하는 방법으로, 부족한 데이터셋의 빈틈을 채워줄 수 있는 방법

'실습 & 활동 > LG Aimers' 카테고리의 다른 글
| Module 3. 지도학습 (분류/회귀) - Advanced Classification (0) | 2023.01.24 |
|---|---|
| Module 3. 지도학습 (분류/회귀) - Linear Classification (0) | 2023.01.19 |
| Module 3. 지도학습 (분류/회귀) - Gradient Descent (0) | 2023.01.17 |
| Module 3. 지도학습 (분류/회귀) - Linear Regression (0) | 2023.01.16 |
| Module 1. AI 윤리 (0) | 2023.01.02 |



