
지금까지 고안된 XAI 기법들을 정량적으로 비교하고 평가하는 방법에는 어떤 것들이 있는지 살펴보자
Metrics 1. Human-based visual assessment
가장 단순한 XAI 기법 평가 방식
: 사람들이 직접 해당 방법들이 만들어낸 설명을 보고 비교 평가하는 방식이 존재
AMT test
AMT 방법은 2가지의 XAI를 직접적으로 비교하여 예측과 예측에 대한 설명을 추출한 뒤 사람들이 그 설명을 보고 이 모델이 어떤 예측에 대한 설명을 한 것인지를 맞춰보는 방식
ex) 모델의 설명이 말을 하이라이트 하고있을 때 사람들은 그 모델이 말이라 예측했다고 생각했을 것이고 만약 그 생각이 모델의 예측과 동일하다면 해당 설명은 잘 되었다고 볼 수 있음
아래 그림은 AMT test를 통해 guided Backprop와 Guided Grad-CAM 방식을 비교한 경우고 여기서는 Guided Grad-CAM이 높은 점수를 얻었음

주어진 이미지에 대해 모델이 사람이라고 예측했을 때 사람에 대한 2가지 다른 설명을 보여주고 어느 쪽 설명이 더 좋은지(사람에 가까운지) 고르는 방식 → 이 방식도 사람이 관여함
아래 그림에서 확인할 수 있듯 해당 테스트도 Guided Grad-CAM 방식이 더 좋다고 나옴

Strength
사람이 개입하기 때문에 쉽게 비교가 가능함
Weakness
사람이 직접 진행하기 때문에 값도 비싸고 시간도 오래걸림
Metrics 2. Human annotation
: 사람들이 이미 만들어 놓은 annotation을 이용하는 방식
object detection이나 semantic segmentation 모델을 학습하기 위한 학습 데이터셋에서는 아래 그림처럼 주어진 이미지에 대한 객체의 bounding box나 pixel label에 labeling이 되어있는 semantic segmentation map이 이미 제공되고 있음

Pointing Game
: Bounding box를 활용해서 평가하는 방법
각 이미지 i에 대한 bounding box B가 주어질 때 각 이미지에 대한 설명 h를 구했다고 하자
예를 들어 Grad-CAM의 경우, Grad-CAM의 설명 중에서 가장 중요도가 높은 픽셀 p가 주어진 bounding box안에 들어가는지를 보고 평가를 진행함
위의 고양이 그림에서 고양이의 bounding box가 있을 때 XAI 방법에서 가장 중요하다고 보여주는 픽셀이 사람이 만든 bounding box 안에 있는 경우 좋은 설명이라고 가정하는 것에서 출발
→ 각 이미지마다 가장 높은 설명값을 갖는 픽셀이 bounding box 안에 들어가는 정확도를 계산해서 평가를 함

Weakly supervised semantic segmentation
: 어떤 이미지에 대해서 Classification label만이 주어져 있을 때 그것을 활용하여 pixel별로 객체의 label을 예측하는 semantic segmentation을 수행하는 방법
여기서 Weakly supervised라고 하는 이유는 pixel별로 정답 label이 다 주어져 있지 않기 때문임
이때 classification label만 있으면 그것을 이용해 이미지 classifier를 만들 수 있고 그에 대한 설명을 구할 수 있음
그렇게 구한 설명 즉, 이미지 내에서 중요한 pixel들을 하이라이트 했을 때 이를 이용해 pixel별 label 또는 segmentation map(SEC with Grad-CAM)을 구할 수 있음
이렇게 구한 segmentation을 정답 segmentation map(Ground-Truth)과 비교해서 평가 함
여기서 평가하는 방식으로 IoU(Intersection over Union)가 쓰이고, 이는 정답 Map과 위의 과정으로 구한 segmentation map이 얼마나 겹치지는지를 평가하는 metric임
최종적으로 이러한 metric 값을 통해 XAI 기법으로 만들어낸 semantic segmentation 결과가 좋을수록 XAI가 더 좋다고 판단함

Weakness
1. 매번 사람이 직접 activation을 제공하는데, 이를 처리하는 비용이 높고 데이터를 구하기 쉽지않음
2. bounding box나 segmentation label이 진짜 좋은 설명을 제공하는 여부가 명확하지 않은 문제점이 있음
Metrics 3. Pixel perturbation
: pixel들을 교란함으로써 모델의 출력 값이 어떻게 변하는지를 직접 테스트 해보는 방식
아래 그림에서 주어진 이미지를 보고 모델이 성이라고 분류했을 때 가리지 않은 이미지에서의 성에 대한 분류 score가 11인데, 일부를 가리고 모델에 넣으니 score가 떨어졌음
→ 즉, 어디를 가리느냐에 따라 score가 달라지는데 이때 score를 많이 변하게 하는 부분이 중요한 부분이라고 생각할 수 있음

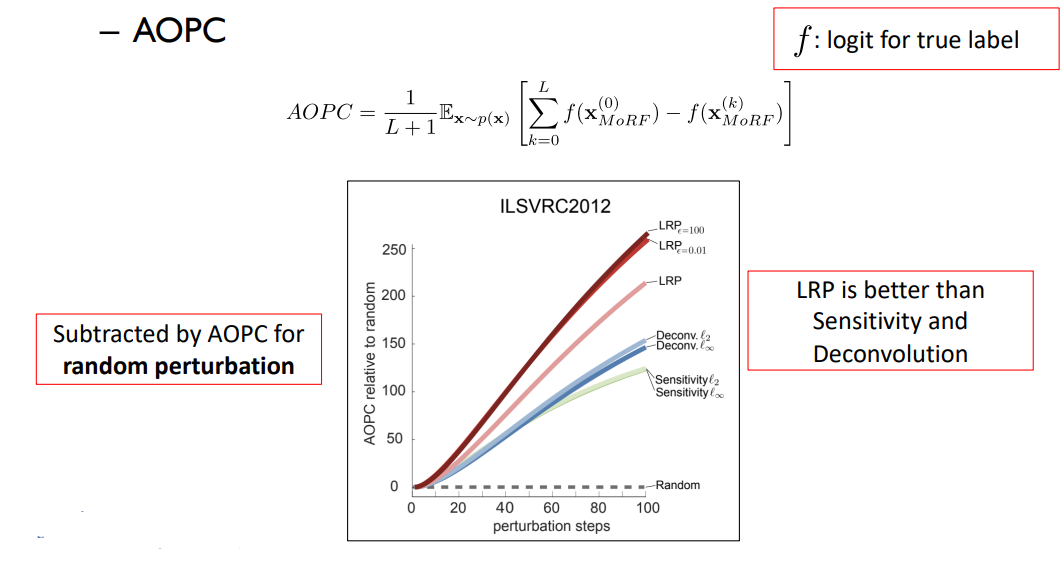
AOPC (Area Over the MoRF Perturbation Curve)
: 주어진 이미지에 대해 각각의 XAI 기법이 설명을 제공하면, 제공한 설명의 중요도 순서대로 각 픽셀들을 정렬하여 그 순서대로 픽셀들을 교란했을 때 원래 예측한 분류 score 값이 얼마나 빨리 바뀌는지를 측정하는 기법임
만약 어떤 XAI 기법들이 만들어낸 중요도 픽셀들을 중요도 순서대로 교란(랜덤한 픽셀 값으로 바꾸는걸 의미)했을 때 모델의 출력 score가 떨어질 것이고, 떨어지는 graph를 생각해볼 수 있음
→ 즉, 교란이 많이 발생할 수록 출력 score는 떨어짐
가로축: 교란한 pixel들의 숫자 / 세로축: 모델의 출력 score
아래 그래프에서 그래프의 기울기가 가파를수록 score가 더 빨리 떨어짐을 의미하여, 정렬된 score를 제공한 설명방법이 더 좋은 설명이라고 판단함
아래 그림에서는 LRP가 우수한 성능을 보임을 알 수 있음
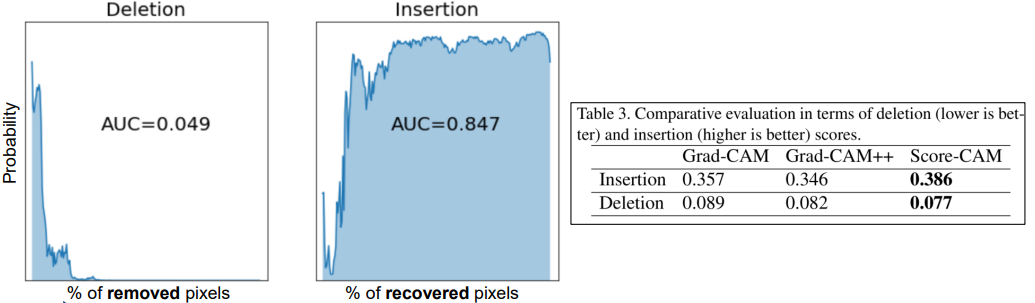
Insertion and Deletion
Deletion
deletion은 aopc처럼 XAI에서 제공한 중요 순서대로 픽셀 하나하나 지워가며 얼마나 분류 score 값이 떨어지는지 보는 것으로 aopc와는 반대로 curve의 아래쪽 면적을 구함 → 즉, deletion 값이 작을수록 좋은 설명임
Insertion
insertion은 백지 상태의 이미지에서 중요한 픽셀 순서대로 픽셀을 추가해가면서 classifier에 출력 score 값이 올라가는 그래프의 아래 면적을 구함 → 즉, 면적이 클수록 좋은 설명임
Strength
사람의 직접적인 평가나 annotation을 활용하지 않으면서도 객관적이고 정량적인 평가 지표를 얻을 수 있음
Weakness
주어진 입력 데이터를 지우거나 추가하는 과정을 통해 model 출력 score 값의 변화를 보는데, 이런 변화가 머신러닝의 주요 가정을 위반하는 경우가 존재함
→ 이미지의 어떤 픽셀을 지우고 model에 넣었을 때 해당 이미지들은 model을 학습시킨 학습 이미지와 다르기에 출력 score의 변화가 정확하다고 보기 어려운 것
ex) 아래 그림의 경우 교란된 픽셀이 balloon이라는 클래스의 score을 상승시켜 성에 대한 정확한 식별을 방해할 수 있음

Metrics 4. ROAR(RemOve And Retrain)
: XAI 기법이 생성한 중요한 픽셀을 지우고나서 지운 데이터를 활용해 모델을 재학습한 뒤 정확도가 얼마나 떨어지는지를 평가해보는 방법을 취하는 기법
XAI가 중요하다고 한 픽셀을 지우고 학습해본 뒤 해당 클래스에 대한 정확도가 많이 감소할 경우에는 좋은 설명으로 취급하고, 그렇지 않으면 설명이 정확하지 않다고 결론을 냄
Strength
AOPC, Insertion, Deletion에 비해 조금 더 객관적이고 정확한 평가를 할 수 있음
Weakness
픽셀을 지우고나서 모델을 매번 재학습해야하므로 계산복잡도가 매우 높아짐

XAI 방법의 신뢰성에 관한 연구

Sanity checks 1. Model randomization
: 이미지에 대한 예측 결과를 얻고, 결과에 대한 설명을 픽셀별로 하이라이트 하는 방법들은 Edge Detector와 같이 이미지 내 object를 하이라이트 하는 것을 볼 수 있었음
→ 이런 방식으로 객체들을 잘 찾아낸다고 해서 좋은 설명 방법이라고 할 수 있는지 의문이 생김
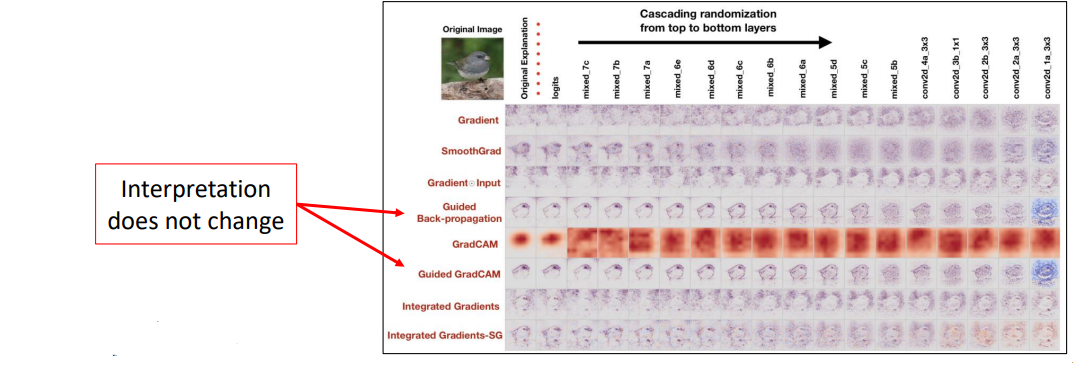
위의 방식으로 만들어진 설명들을 온전히 믿을만한지 테스트해보는 방법을 제안한 것이 Model randomization임
그 과정은 주어진 분류모델의 위쪽 레이어부터 모델의 계수들을 순차적으로 randomize한 후, 얻어지는 설명을 구해보는 테스트를 진행함
이를 통해서 randomization을 진행해도 크게 설명이 바뀌지 않고, 여전히 객체를 하이라이트하는 마치 Edge Detector와 같이 동작하는 XAI 기법을 걸러낼 수 있음
ex)
아래 그림에서 열에 해당하는 부분이 오른쪽으로 갈수록 완전한 random model에 대한 설명임
→ 정상적인 설명 방법이라면 오른쪽으로 이동할수록 아무 의미없는 설명이 나와야 함
왜냐하면, random한 모델이 random한 예측 결과를 설명하는 것이 아무 의미가 없기 때문
하지만, 아래 그림에서는 guided back-propagation과 guided Grad-CAM 방법들의 설명을 보면 오른쪽 부분으로 가더라도 크게 설명이 바뀌지 않고 새 부분을 하이라이트하고 있음
Sanity checks 2. Adversarial attack
: XAI 기법에 적대적 공격도 가능함
어떤 이미지에 대한 설명을 아래 그림의 1열처럼 얻는다고 생각하면 별 문제가 없이 정상적으로 강아지의 중요한 픽셀들을 잘 강조하고 있는 것을 알 수 있음
하지만, 입력 이미지의 픽셀들을 아주 약간만 바꾸면 예측은 강아지를 내보내고 있지만 2열의 이미지처럼 이상한 설명을 도출해냄을 알 수 있음

위 예시처럼 adversarial attack은 입력 이미지에 약간의 변형을 가하게 되면 classifier의 예측 결과를 완전히 다르게 만들 수 있다는 내용인데 여기서는 classifier의 예측은 그대로 유지하면서 설명 방법을 이상하게 공격할 수 있다는 내용임
이러한 설명 방법이 공격받을 수 있는 이유가 주어진 딥러닝 모델의 decision boundary가 smooth 하지않고 울퉁불퉁 형성되기 때문이라고 설명함
→ 즉, 많은 설명 방법들이 gradient와 연산된 값을 사용하는데 decision boundary가 불연속적으로 나오게 된다면 gradient의 방향이 급격하게 변할 수 있어 조금만 입력이 바뀌어도 gradient는 아주 많이 바뀔 수 있다는 말임
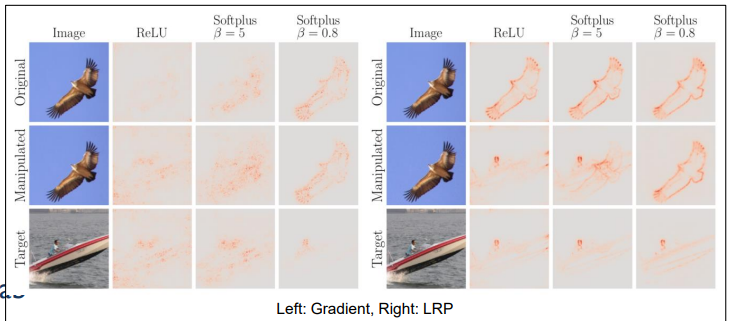
이때, activation function으로 ReLU를 사용하지 않고 softplus를 사용하면 adversarial attack에 좀 더 강건한 모델 만들기가 가능함

아래 그림처럼 ReLU 대신 softplus를 사용할 경우 adversarial attack에 좀 더 강건한 것을 확인할 수 있음
Sanity checks 3. Adversarial model manipulation
: 적대적 공격이 입력을 바꿔서만 가능해지는 것이 아니라 모델이 조작될 수도 있음
예를 들어 특정 model을 만든 개발자가 XAI 방법을 통해 model이 편향되었음을 알았을 때, 해당 model을 편향되지 않도록 고치게 하는 재학습을 진행하는 것이 아니라 model 계수(w)를 조금씩만 조작해서 model의 정확도는 차이가 없지만 XAI로 만들어낸 설명만 마치 공정한 model인 것처럼 나오게 조작이 가능함
ex) 성인 소득 데이터에서 각 개인이 연봉을 5만불 이상으로 받냐 이하로 받냐를 예측하는 부분에서 원래 설명이 파란색 bar처럼 나왔다고 했을 때 가로축에 해당하는 부분이 예측하는데 얼마나 중요하게 쓰였는지 나타냄
아래 모델은 인종이나 성별을 중요한 설명 방법으로 이용하고 있기 때문에 이 모델은 편향됐다고 할 수 있음
하지만 이 모델의 편향성을 고치지 않고 설명만 주황색 bar처럼 바꿀 수 있음
이렇게 조작하면 XAI를 통해 모델 편향성을 검증했을 때 편향성에 안 걸릴 수 있음
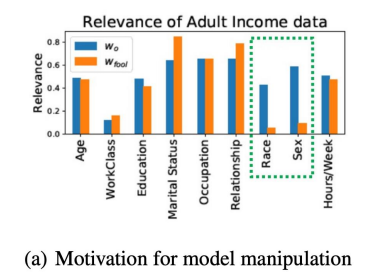
이러한 방법은 입력을 조작하는 것과는 다른 공격이고 이러한 공격 기법은 정확도의 감소는 거의 없지만 전체 validation set에 대한 설명이 모두 조작됨을 보임
→ 즉, 실제 모델은 여전히 원래 중요하게 생각했던 것을 보고있고 설명만 조작된 것임을 알 수 있음

'실습 & 활동 > LG Aimers' 카테고리의 다른 글
| Module 7. 시계열 데이터 및 AI 모델 성능 최적화 - 순환 신경망 기반의 시계열 회귀(2) (0) | 2023.02.01 |
|---|---|
| Module 7. 시계열 데이터 및 AI 모델 성능 최적화 - 순환 신경망 기반의 시계열 회귀(1) (0) | 2023.01.30 |
| Module 5. Explainable AI (XAI) - 2 (0) | 2023.01.26 |
| Module 5. Explainable AI (XAI) - 1 (0) | 2023.01.25 |
| Module 3. 지도학습 (분류/회귀) - Ensemble (0) | 2023.01.25 |



