RNN(순환 신경망)의 변종들
: 가지고 있는 정보를 시간의 역방향(미래 → 과거)으로 처리하면 모델의 성능을 높일 수 있음
ex) 번역기
RNN Variations: Bidirectional RNN
: 정보의 입력을 시간의 순방향과 역방향 관점에서 함께 처리하여 모델의 성능을 높이자는 아이디어를 갖고 있음
: 나중에 최종적인 output(y_t)를 내고자 할 때 순방향의 hidden vector와 역방향의 hidden vector를 옆으로 이어 붙여 사용을 하게 되는 방식임

RNN Variations: Deep-Bidirectional RNN
: RNN의 hidden layer의 층을 깊게 쌓은 모델
(딥러닝에서 neural network에 층을 깊게 쌓으면 성능을 높일 수 있었다는 원리를 기반으로 제시됨)
단, RNN은 CNN(이미지 처리에 사용하는 모델)과 다르게 층을 많이 쌓을수록 지속적인 성능 향상을 보장하진 않으므로 hidden layer를 쌓지 않거나 최대 2~4개 층 정도만 쌓는 것이 maximum 층의 개수임
RNN: Attention
: 어느 시점 정보가 RNN의 최종 출력 값에 영향을 미치는지를 알려줄 수 있는 메커니즘
두 가지 대표적인 attention 메커니즘
✓ Bahadanau attention
: attention 매커니즘을 구현하기 위해서 별도로 다시 한 번 모델을 학습해야 됨
✓ Luong attention
: 별도로 학습하지 않아도 attention score를 산출할 수 있음
: 그래서 더 많이 사용됨
RNN with Attention
: Vanilla RNN과 유사하게 각 시점별로 Hidden state의 정보가 전달 됨
attention 시스템이 없는 경우)
x_END라는 신호를 주면 h*라고 하는 점에서 바로 y 값을 예측하게 됨
attention 시스템이 있는 경우)
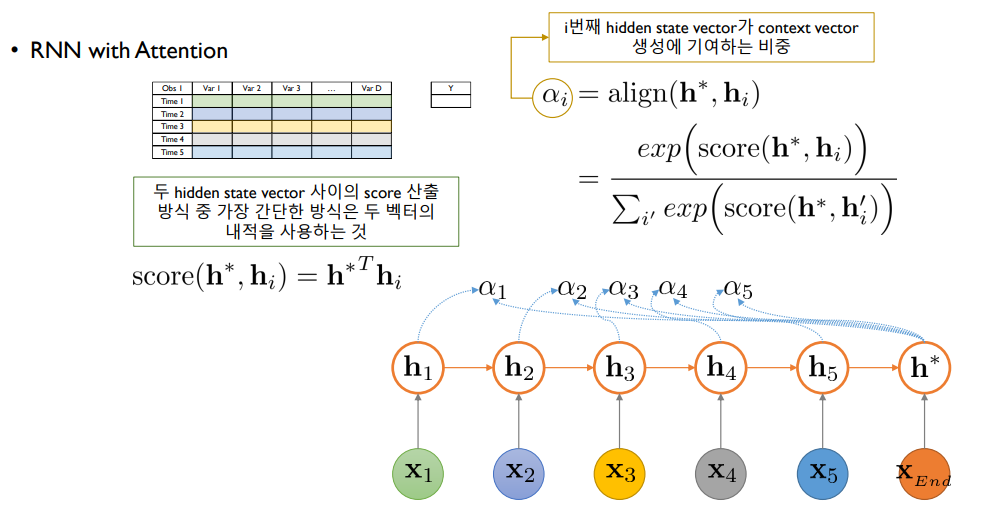
가장 마지막의 hidden state 정보(h*)와 첫번째 hidden state(h1)와의 어떤 a라는 유사도 또는 기여도를 산출함
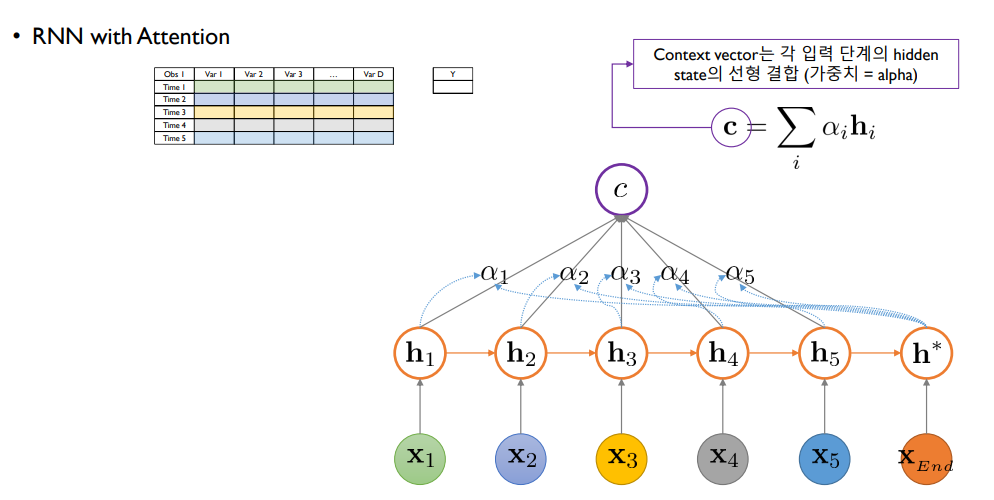
이러한 과정을 각각의 hidden state들을 방문하면서 진행해 a1~a5까지 산출한 후 과거에 한 번 쓰였던 hidden state들을 그대로 버리는 것이 아니라 아래 그림처럼 h1~h5와 a1~a5와의 선형 결합을 통해 c라는 context vector를 생성
이렇게 만들어진 c와 마지막 시점에서의 hidden state vector(h*)를 결합해 h틸다(h~)라고 하는 새로운 hidden state vector를 만들고 이걸 통해 y를 예측함
attention 시스템 사용의 장점
: 사용하지 않았을 때보다 훨씬 더 성능이 향상됨
: a라는 값이 결국 0부터 1 사이로 나오면서 모든 알파들의 값을 더했을 때는 1이기 때문에 예측을 하는데 있어서 몇 번째 시점이 가장 중요하게 역할을 했는가를 알 수 있음
a의 역할에 대한 추가적인 설명
a_i: i번째 hidden state vector가 context vector 생성에 기여하는 비중이면서 나중에 해석을 할 때는 해당하는 시점이 얼마나 최종 의사결정에 영향을 많이 미쳤냐에 대한 기여도임
이 기여도는 h*라고 하는 제일 마지막에 해당하는 hidden state vector와 i번째 hidden state vector의 어떤 두 사이의 함수 관계인데 그 함수는 결국 a를 0부터 1 사이로 만들기 위한 softmax function에다가 안에 있는 score라는 함수를 적용하게 됨

이 score는 두 hidden state vector가 유사할수록 큰 값, 유사하지 않을수록 작은 값을 나타나게 됨

전체 과정
context vector 역할에 대한 추가적인 설명
지금까지 계산해왔던 각 시점들의 hidden state vector와 a의 선형 결합을 통해 만들어짐
LSTM, GRU, Vanilla RNN처럼 기존에 attention이 없는 구조에서는 중간 시점에 해당하는 hidden state h들의 정보가 버려지고 가장 마지막 시점에 있는 h만 사용됨
→ 하지만 attention을 활용할 경우 중간 시점에 해당하는 hidden state vector들도 다시 한 번 최종적인 의사결정에 활용될 수 있는 기회를 얻게 됨

전체 과정
h~ 역할에 대한 추가적인 설명
가장 마지막 시점의 hidden state(h*)와 context vector를 concatenation(옆으로 연결)한 vector에다가 W라는 학습 대상이 되는 가중치를 곱한 다음 비선형 활성화를 통해서 만들게 되고 이걸 통해서 최종적으로 예측을 수행하게 됨

전체 과정

최종 예측 과정

최종 Luong attention 수식


'실습 & 활동 > LG Aimers' 카테고리의 다른 글
| Module 7. 시계열 데이터 및 AI 모델 성능 최적화 - 합성곱 기반의 시계열 회귀(2) (0) | 2023.02.02 |
|---|---|
| Module 7. 시계열 데이터 및 AI 모델 성능 최적화 - 합성곱 기반의 시계열 회귀(1) (2) | 2023.02.01 |
| Module 7. 시계열 데이터 및 AI 모델 성능 최적화 - 순환 신경망 기반의 시계열 회귀(1) (0) | 2023.01.30 |
| Module 5. Explainable AI (XAI) - 3 (2) | 2023.01.26 |
| Module 5. Explainable AI (XAI) - 2 (0) | 2023.01.26 |



